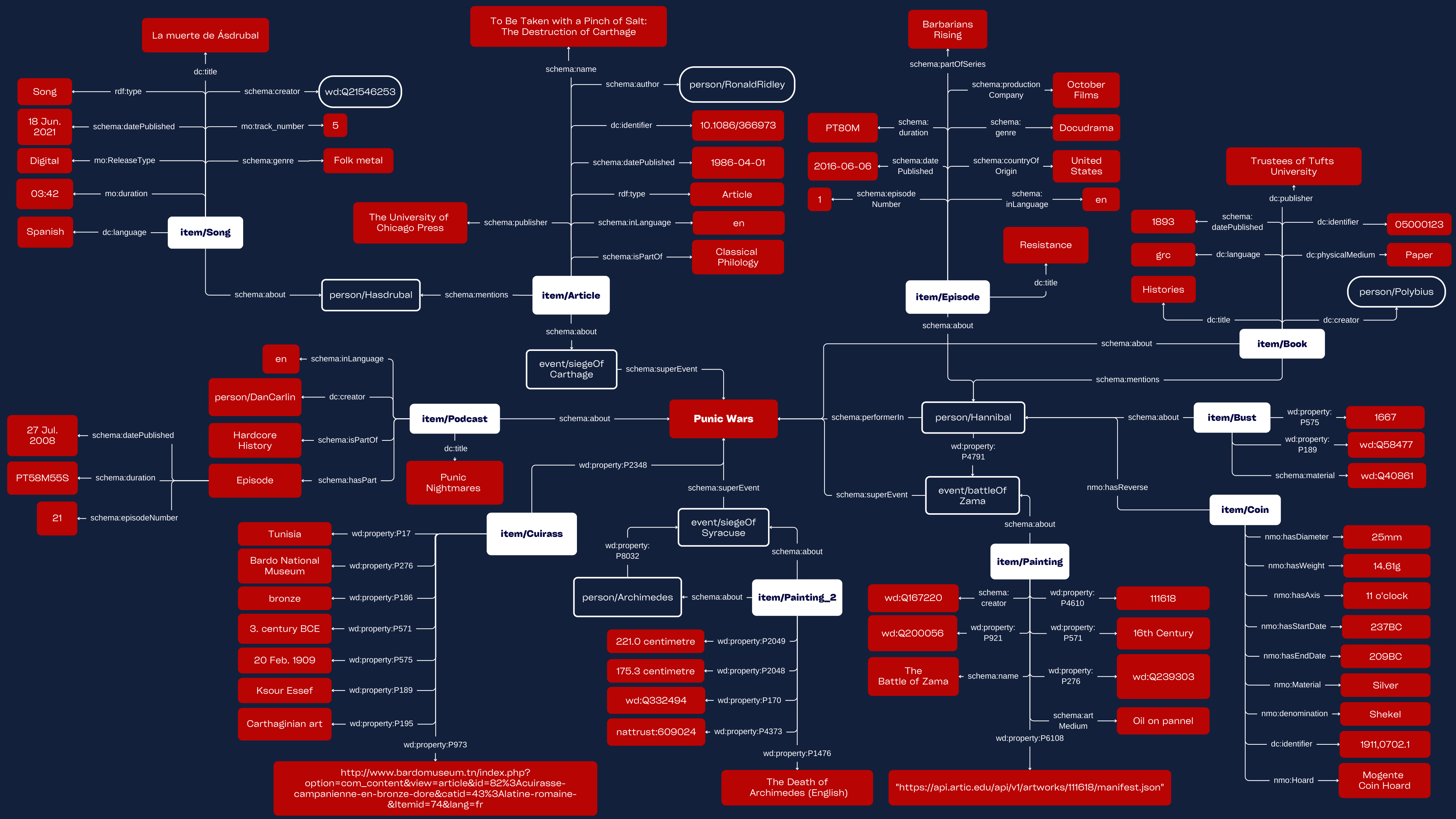
Idea

Circa 264-146 BCE, the ancient Mediterranean region would witness three major conflicts fought between Rome and Carthage. Significant for their lifelong impact on the region, the victory of Rome would shape its rise as the dominant power in the ancient world.
The first Punic War (264-241 BCE) was caused by a complex competition over trade routes and territories in the Western Mediterranean, especially in Sicily and North Africa. It was a naval conflict centred around Sicily with Rome winning and gaining control of the island.
The second Punic War is largely the most famous out of the three wars, where the Carthaginian general Hannibal led his elephant fortified army on an overland reach from Spain across the Alps and eventually into Italy. On his march, he inflicted many taxing defeats on the Roman Empire, despite this the war was lost and Carthage had to cede territories in both Spain and North Africa and pay heavy indemnity to Rome.
The third and final Punic War (149-146 BCE) was sparked by renewed tensions between Rome and Carthage. Viewing Carthage’s presence as a continuous threat to the empire, Rome laid siege to the city and eventually captured it only to destroy it in 146 BCE. Carthage’s downfall allowed Rome a monopoly of control in the Mediterranean region and solidified its dominance.
These wars challenged the notions of warfare in ancient times and pushed two superpowers to concede, adapt and re-adjust. This Linked Open Data project aims to explore the significance of these events in the region by exploring the gains, losses and achievements of the two respective forces.

Items
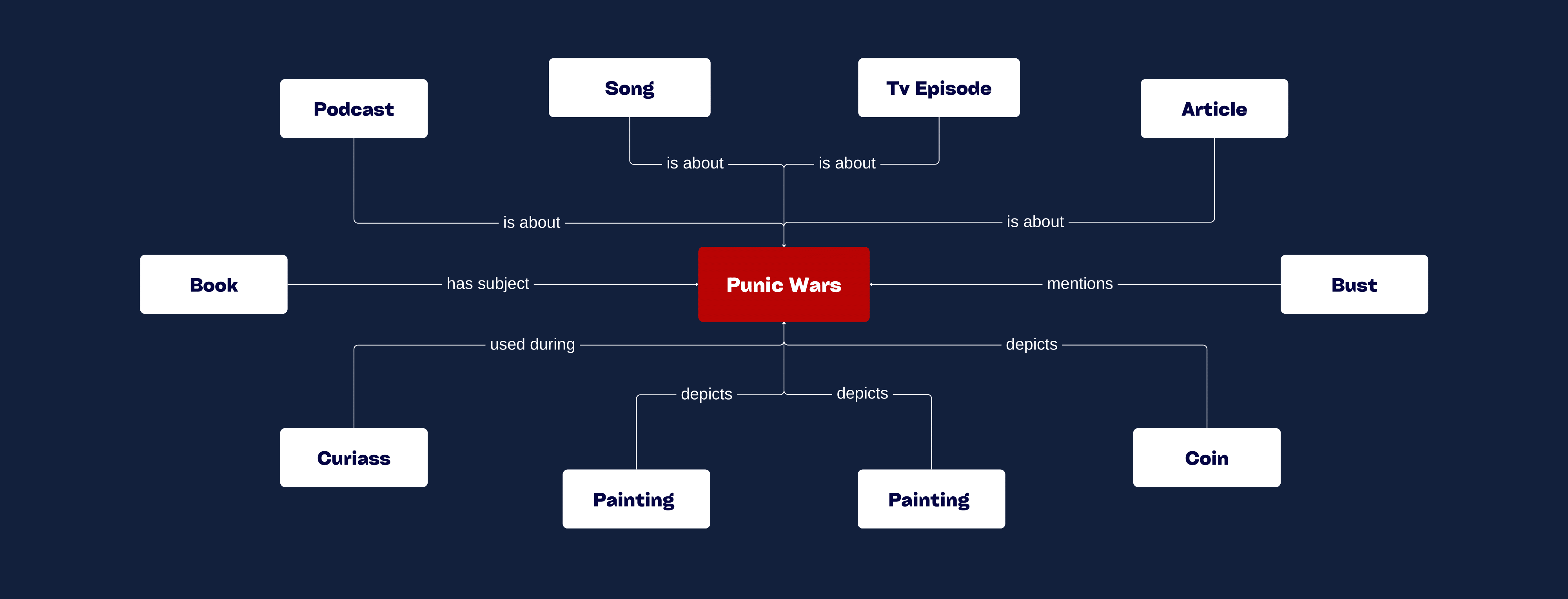
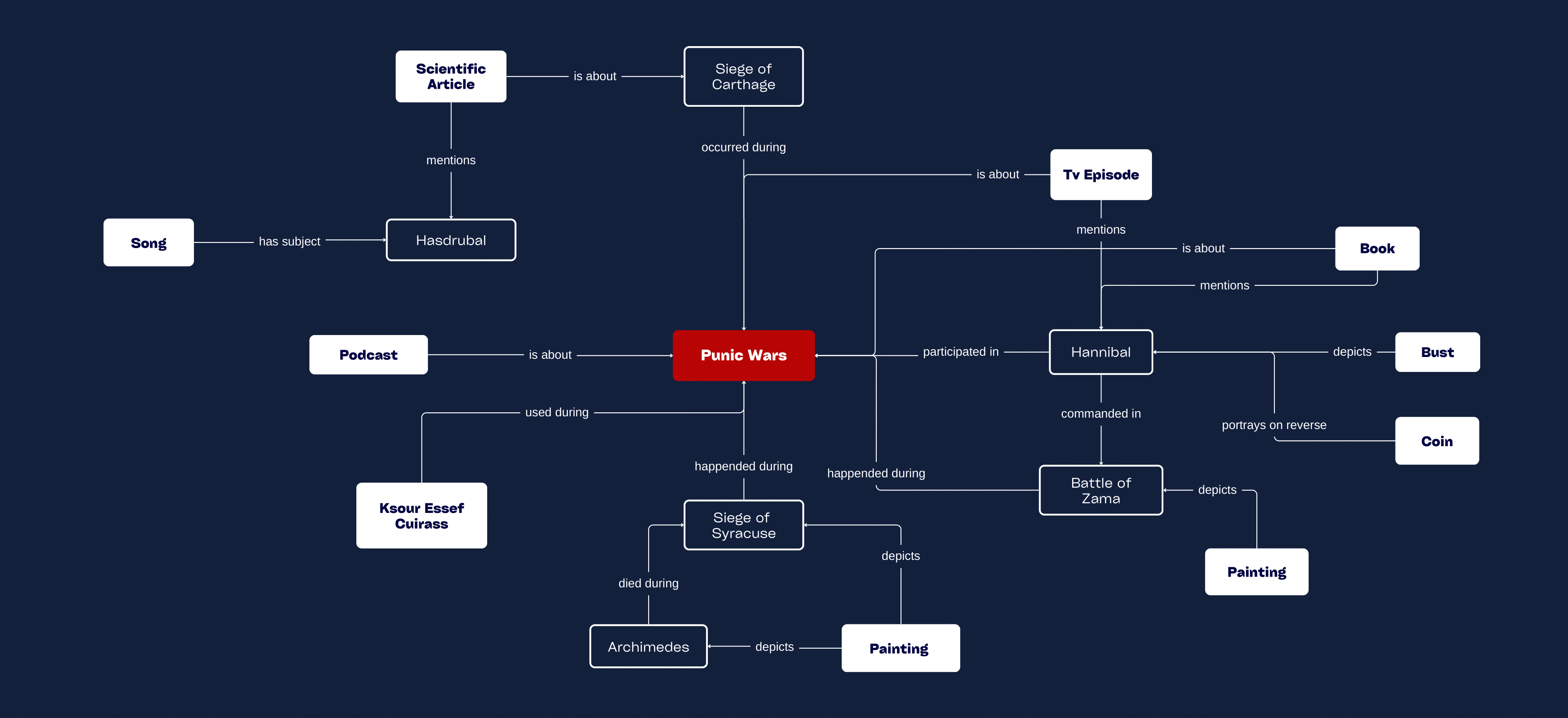
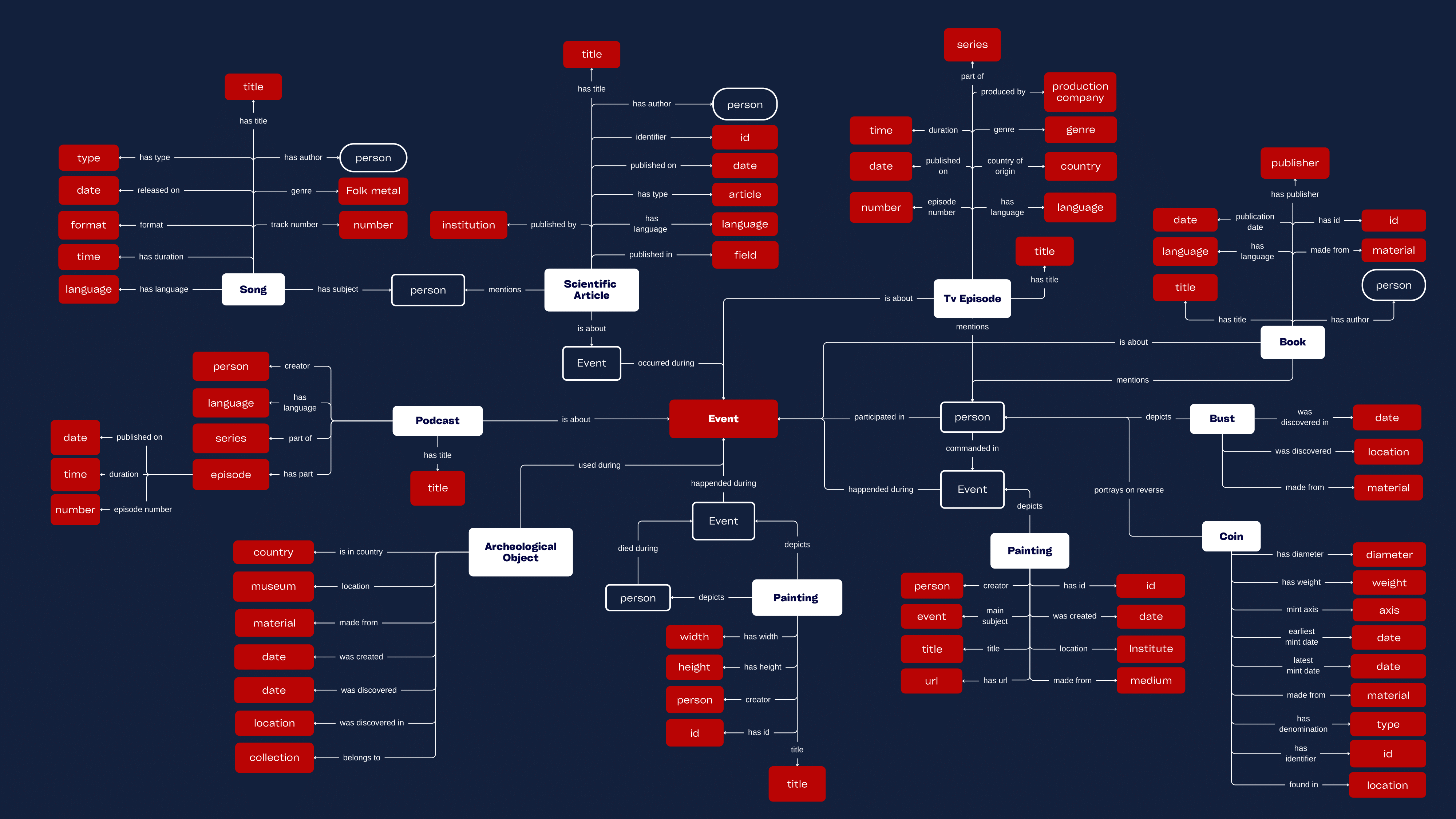
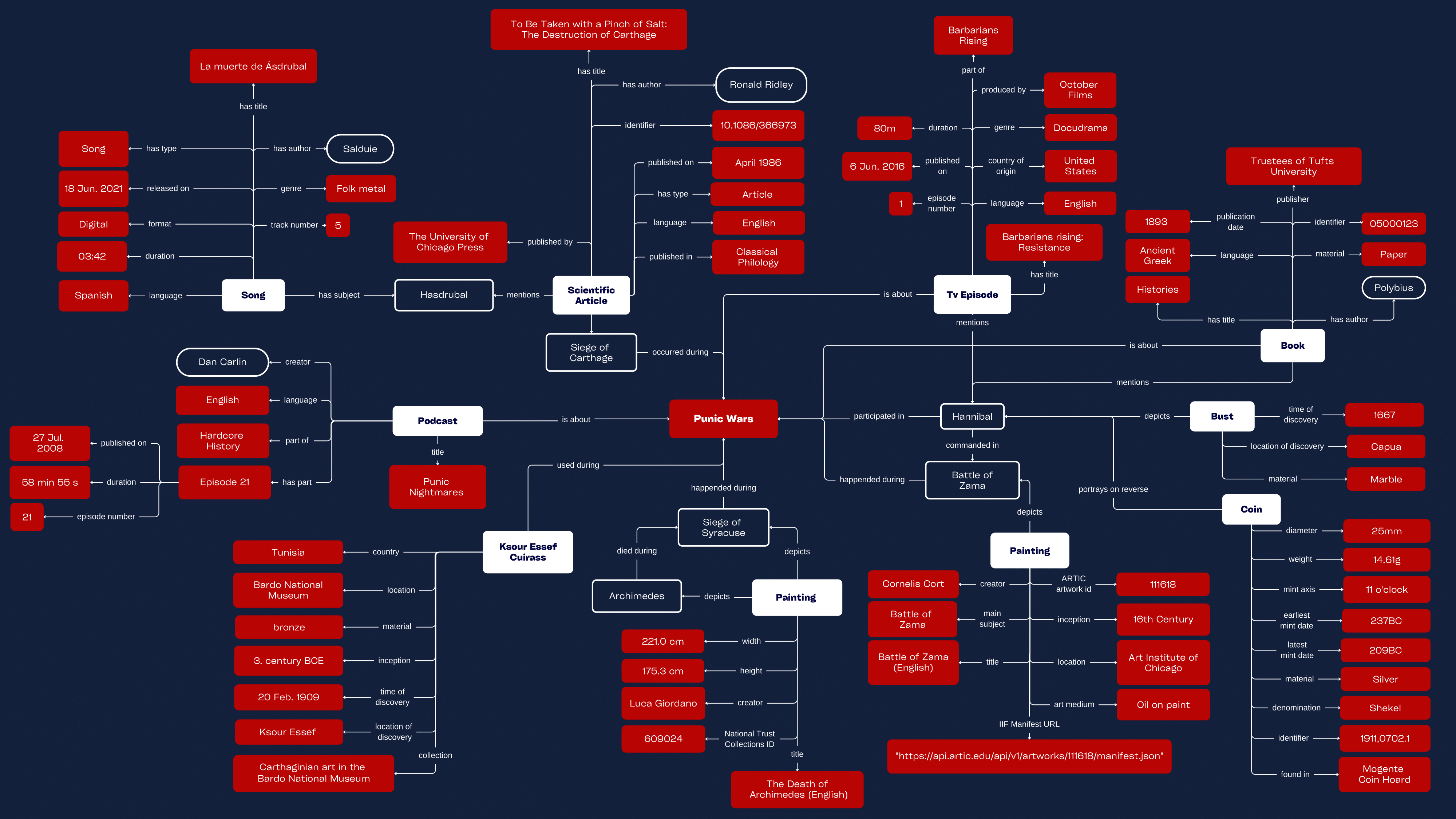
The selected items are objects of relevance to the Punic Wars, inclusive of notable people, places and events; maintaining a historical perspective but also a modern retelling of what transpired.